Email: zdc@chinazdc.com
用户中心

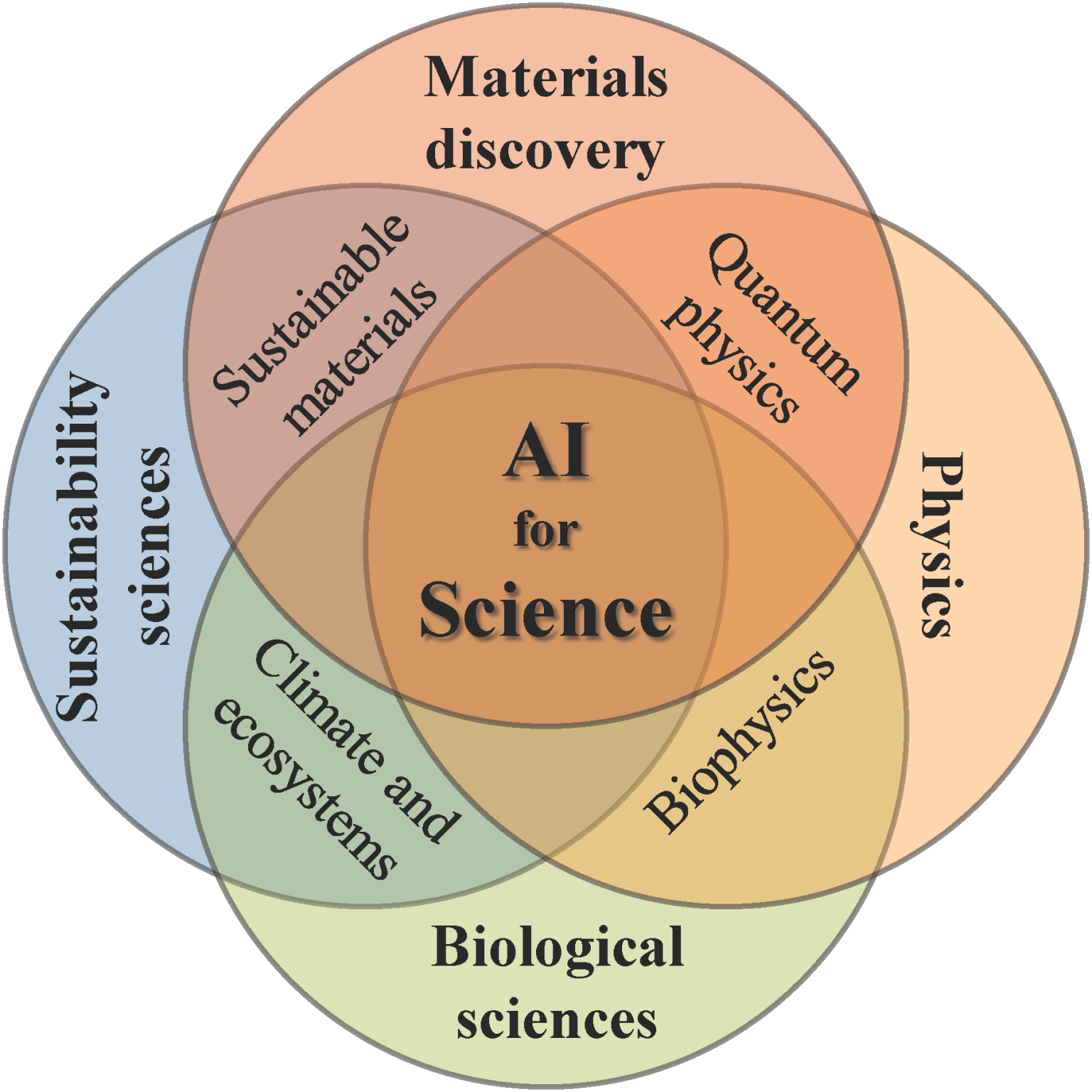
AI for Science:拥抱人工智能,Nature、Science发不停!
2024-05-30 11:27:18
3086
随着人工智能技术的发展,人工智能越来越多地融入科研活动中。从收集整理数据到设计实验,善于借助人工智能的研究者获得了前所未有的效率及洞察力。本文对目前人工智能应用在科研活动中的一些典型进展进行了分类总结,涵盖的领域包括生物学、神经科学、医学、化学、物理学以及地球科学。本文旨在总结人工智能与科研工作结合的经验、进展,并希望能够给各位读者的科研工作提供新的灵感。
生物学
蛋白质结构预测与设计
自从DeepMind基于深度学习技术开发的AlphaFold2在蛋白质结构预测中大放异彩,大量机构和公司纷纷投入到基于人工智能的蛋白质建模与设计研究中。其中,RosettaFold-AA[1]和AlphaFold-latest[2]将人工智能的研究拓展到蛋白质与其他生物分子(如小分子、蛋白质、核酸等)的相互作用预测中;Hannah等[3]则发现通过利用序列相似性对多序列比对(multiple-sequence-alignment, MSA)进行聚类可以使AlphaFold2采样到不同的蛋白质构象。
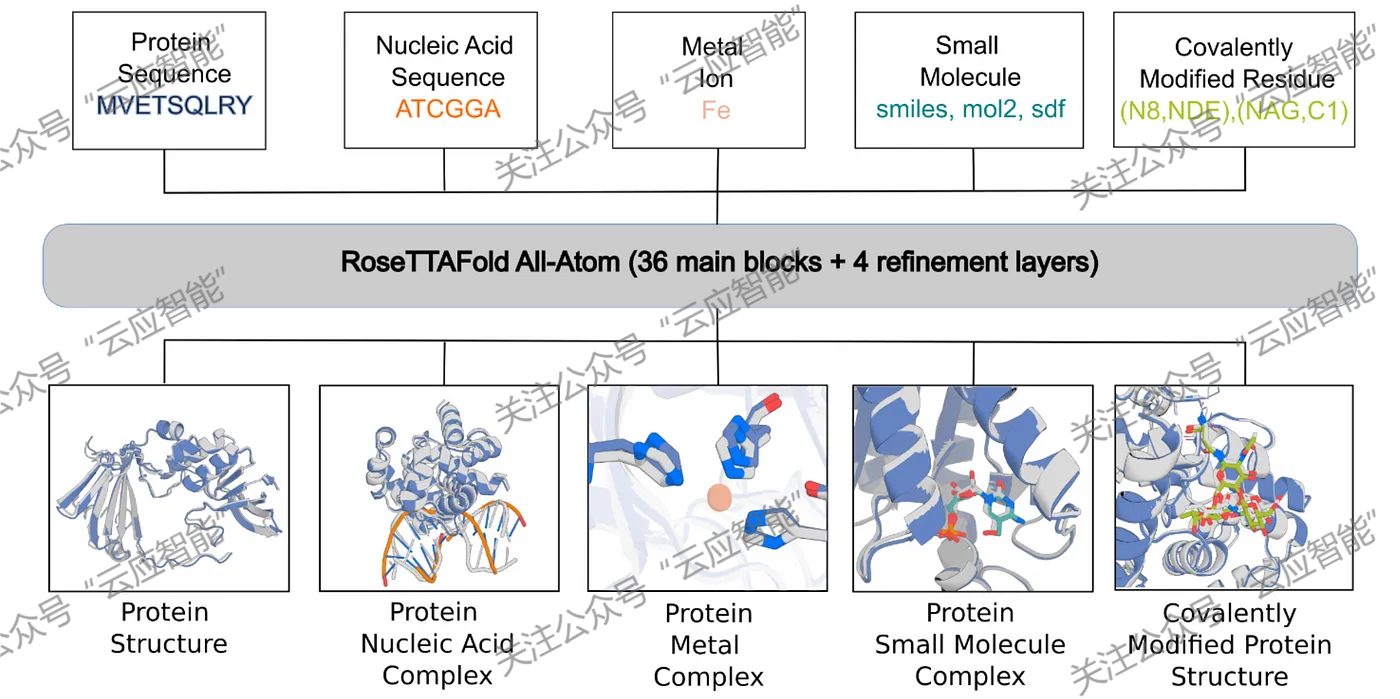
RosettaFold-AA示意图
在理解蛋白质的结构和功能之外,蛋白质设计侧重于创造新蛋白质或修改现有蛋白质以实现特定结构和功能。随着人工智能技术的发展尤其是生成扩散模型的发展,RFDiffusion[4]和Chroma[5]开发了在欧几里得空间(旋转、平移和反射)对称性下生成新蛋白质的生成扩散模型。除了全新的算法设计之外,研究者还提出了蛋白质结构或功能的设计优化技术,如结合目标及功能基序进行条件设定,并设计算法模型蛋白质结构或功能进行启发式优化。
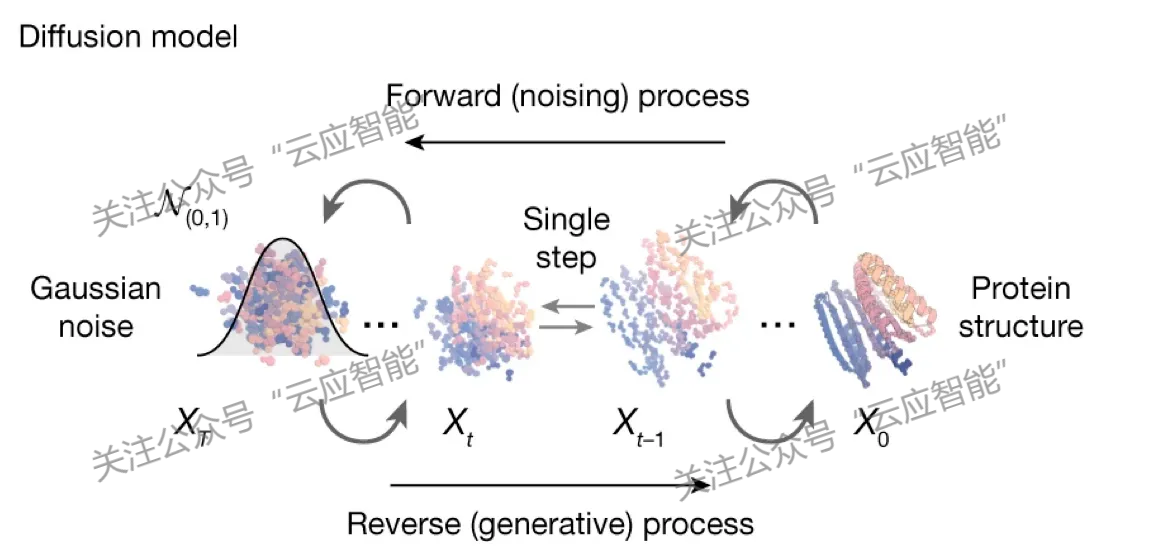
RFDiffusion示意图
生物学基础模型
基础模型(Foundation Model)是由海量数据预训练而成的通用大规模人工智能模型,具备在多种下游任务中高效迁移学习的能力。这些模型捕捉了广泛的模式和特征,能够在文本、图像等多种数据类型上展现出色的性能,从而提升了人工智能系统的通用性和效率。随着基础模型已经在通用的自然语言处理和计算机视觉领域证明了其有效性,研究者也开始思考是否能够在生物学领域构建行之有效的基础模型。目前,如protein folding[6], cross-species cell embedding[7]等,已经有许多为各种生物学研究任务提供人工智能基础模型的工作。在这些研究中,类似于蛋白质结构预测中自监督学习理念也被应用于DNA和RNA的相关研究中,ATOM-1[8]的理念是基于RNA序列的化学映射数据训练seq2seq模型,该方法已经初步展示出其在结构预测中的实用性。在细胞生物学领域也涌现出许多面向单细胞的基础模型。例如Cui等[9]、Hao等[10]以及Theodoris等[11],他们将语言大模型推广到单细胞基因表达分析中,并在批次效应校正及整合等标准单细胞分析任务上进行了基准测试。这些模型展示出更强的捕捉生物信号能力,并且其零样本的表现与经过微调的模型相当。虽然目前构建生物学领域的基础模型已经有了一定数量的研究成果,但由于配对数据的稀缺,生物学中领域的基础模型主要是单模态的(专注于蛋白质、分子、疾病等)。BioBridge[12]利用生物知识图谱来学习单模态基础模型之间的转换,从而实现多模态功能。连接不同模态以回答多模态查询将会是一个非常有前景的研究领域。
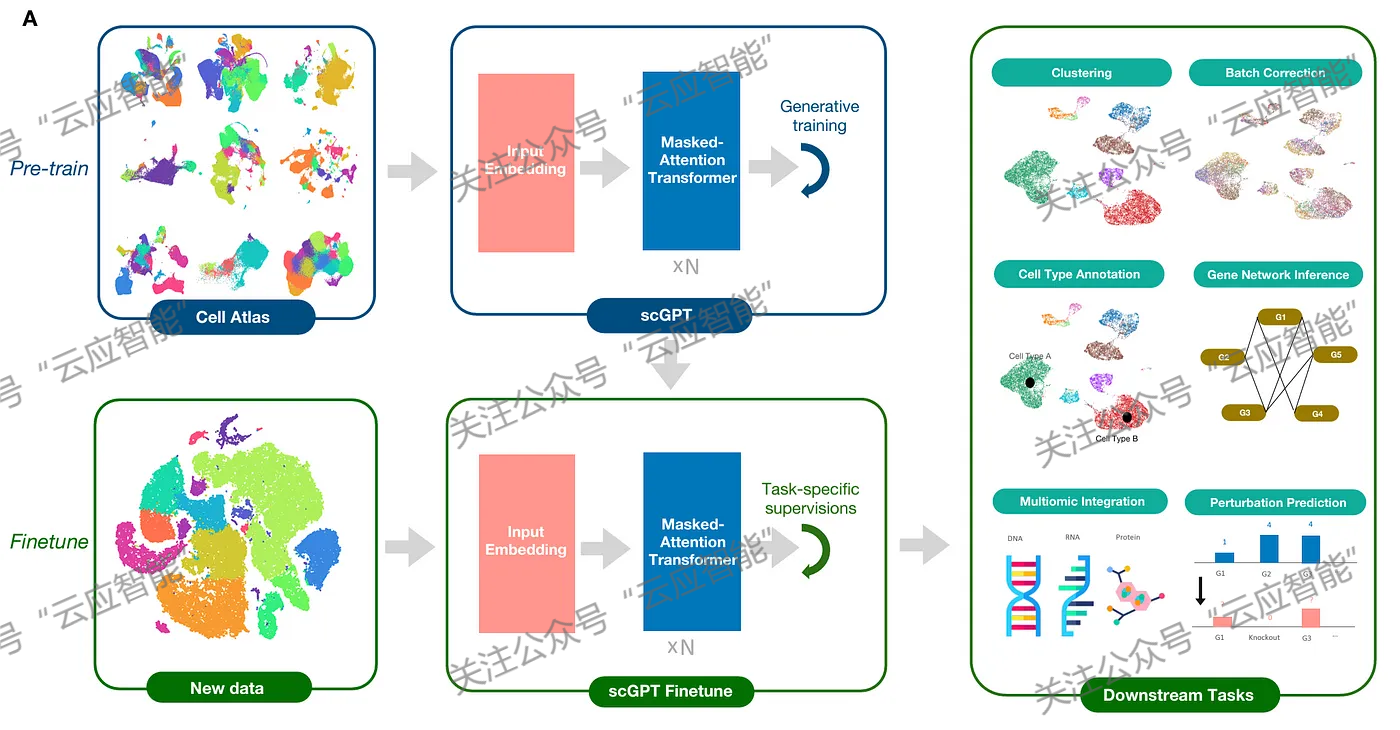
scGPT——单细胞基因表达分析基础模型示意图
生物学大模型应用
生物学研究主要是针对DNA、RNA和蛋白质等生化实体展开,这些实体的规律和模式与人类语言涉及的实体有着天然不同的归纳偏差。然而对生物学的探索和理解主要依赖于人类语言。例如,科学家们通过撰写论文、交流思想和使用文字描述来提出和分享想法,生物学实验也都是按照文本描述进行的。随着语言大模型(LLM)的出现,我们可以发现语言大模型为生物学研究引入了新的可能,并展现出其彻底改变生物科学的潜力。微软研究院的研究团队对语言大模型在生物学中的应用进行了全面研究。他们首先在众多生物学任务上对语言大模型进行了测试,例如序列注释、识别蛋白质功能域、信号通路和设计序列等。同时,他们还利用语言大模型开展数据处理并为液体处理机器人生成代码以相关实验的开展。在生物学中开展大模型应用的另一研究方向是基于大模型的智能体研究。WikiCrow[13]通过浏览大量公共文献并参考维基百科摘要风格,为目前缺乏维基百科文章的15616个人类蛋白质编码基因生成文章草稿。基于大模型的智能体可以作为一种强大的信息整合工具,能够帮助研究者从当前海量的纷杂数据获取有价值信息。
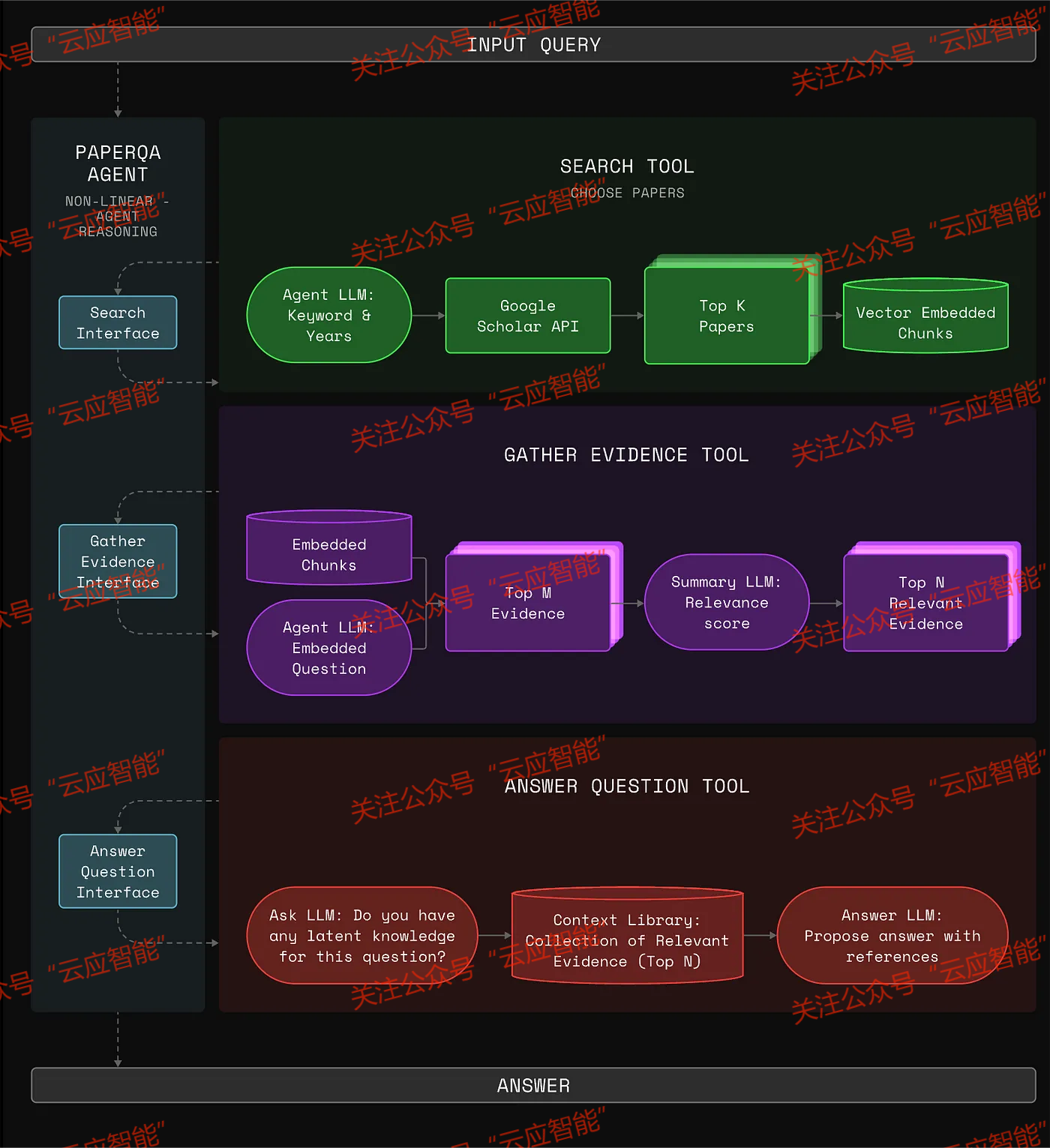
Wikicrow——基于大模型的智能体框架图
生物学图技术应用
生物学是一个多尺度、多模态的互联系统。对这个系统进行有效的建模不仅可以解答生物学基础问题,还能显著促进颠覆性治疗手段的产生。这一互联系统最自然的存储方式即是关系数据库或异构图,这种数据结构存储了几十年来在不同生物模态中开展的实验数据,具备多达数十亿的数据节点。随着人工智能技术引入生物学研究,我们见证了一系列基于图神经网络(GNN)的创新应用,这些应用不仅解锁了新的生物医学能力并回答了一些关键的生物学问题。图神经网络在生物学中的应用之一便是扰动生物学。理解扰动的结果可以带来细胞重编程、靶点发现和合成等方面的进展。GEARS[14]将图神经网络(GNN)应用于基因扰动关系图,并预测以前未观察到的基因扰动结果。神经网络在生物学中的另一值得关注的应用是结合细胞环境的蛋白质表示预测,尽管我们知道到相同的蛋白质在不同的细胞环境中可以表现出不同的功能,但目前对蛋白质表达的预测是固定的。PINNACLE[15]融合图神经网络与蛋白质相互作用网络,明显增强了蛋白质3D结构表示的预测,并在识别治疗靶点上显著优于现有方法。除了预测之外,理解生物现象的潜在机制也至关重要。结合图技术的人工智能方法在识别通路机制的研究中也大放异彩。例如,TxGNN[16]将药物与疾病的关系预测置于生物系统图中从而生成multi-hop可解释路径。这些路径解释了药物在治疗特定疾病方面的潜力。同时,TxGNN也为这些解释设计了可视化,并通过实验证明了它们对临床医生和生物医学科学家决策辅助的有效性。
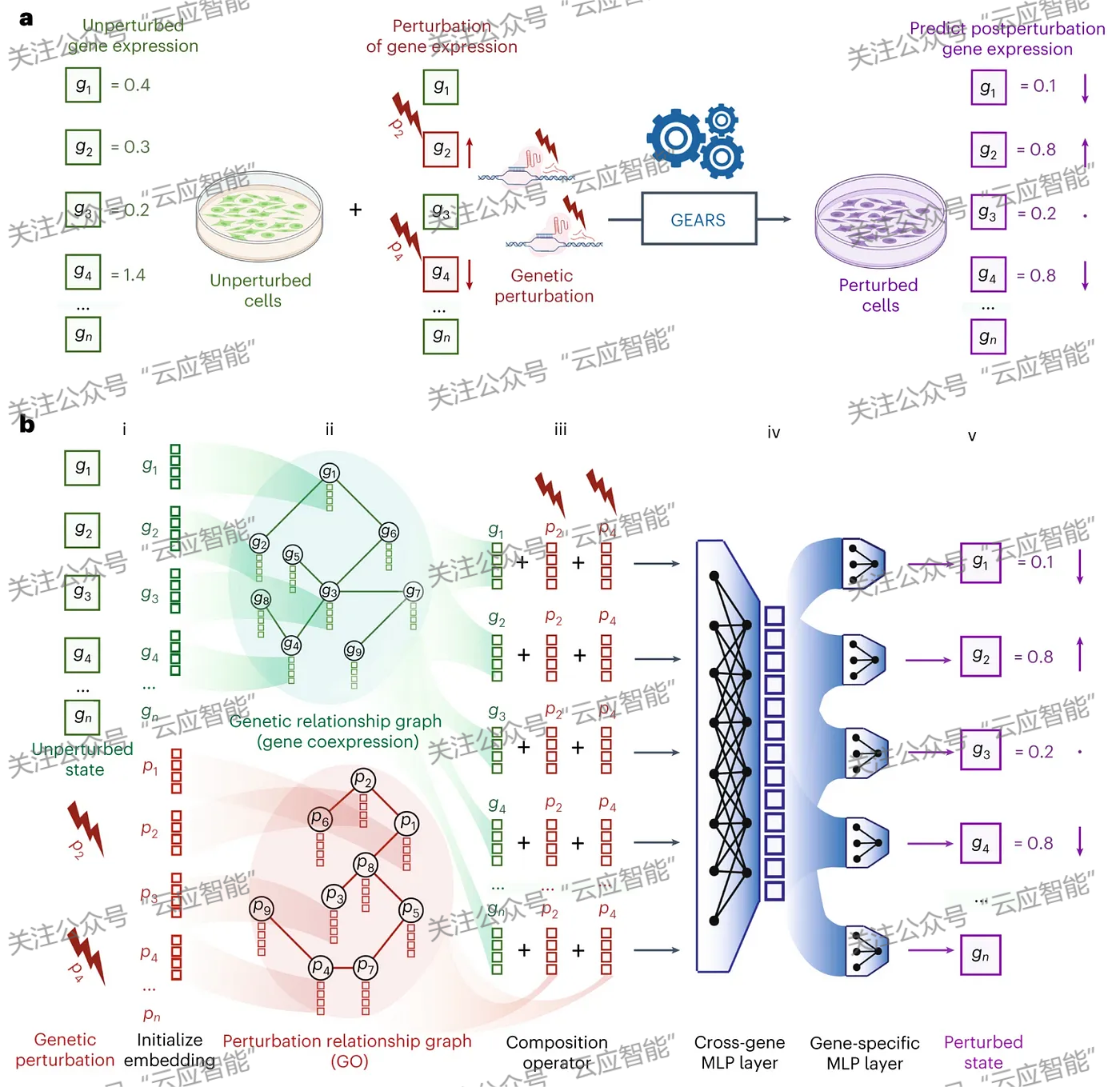
GEARS——图神经网络在生物学中的应用
参考文献
[2] Jumper J, Evans R, Pritzel A, et al. Highly accurate protein structure prediction with AlphaFold[J]. Nature, 2021, 596(7873): 583-589.
[3] Wayment-Steele H K, Ojoawo A, Otten R, et al. Predicting multiple conformations via sequence clustering and AlphaFold2[J]. Nature, 2024, 625(7996): 832-839.
[4] Watson J L, Juergens D, Bennett N R, et al. De novo design of protein structure and function with RFdiffusion[J]. Nature, 2023, 620(7976): 1089-1100.
[5] Ingraham J B, Baranov M, Costello Z, et al. Illuminating protein space with a programmable generative model[J]. Nature, 2023, 623(7989): 1070-1078.
[6] Lin Z, Akin H, Rao R, et al. Evolutionary-scale prediction of atomic-level protein structure with a language model[J]. Science, 2023, 379(6637): 1123-1130.
[7] Rosen Y, Roohani Y, Agrawal A, et al. Universal Cell Embeddings: A Foundation Model for Cell Biology[J]. bioRxiv, 2023: 2023.11. 28.568918.
[8] Boyd N, Anderson B M, Townshend B, et al. ATOM-1: A foundation model for RNA structure and function built on chemical mapping data[J]. bioRxiv, 2023: 2023.12. 13.571579.
[9] Cui H, Wang C, Maan H, et al. scGPT: toward building a foundation model for single-cell multi-omics using generative AI[J]. Nature Methods, 2024: 1-11.
[10] Hao M, Gong J, Zeng X, et al. Large scale foundation model on single-cell transcriptomics[J]. bioRxiv, 2023: 2023.05. 29.542705.
[11] Theodoris C V, Xiao L, Chopra A, et al. Transfer learning enables predictions in network biology[J]. Nature, 2023, 618(7965): 616-624.
[12] Wang Z, Wang Z, Srinivasan B, et al. BioBridge: Bridging Biomedical Foundation Models via Knowledge Graph[J]. arXiv preprint arXiv:2310.03320, 2023.
[13] WikiCrow: Automating Synthesis of Human Scientific Knowledge[EB/OL].[2024-05-21].https://www.futurehouse.org/wikicrow
[14] Roohani Y, Huang K, Leskovec J. Predicting transcriptional outcomes of novel multigene perturbations with gears[J]. Nature Biotechnology, 2023: 1-9.
[15] Li M M, Huang Y, Sumathipala M, et al. Contextualizing protein representations using deep learning on protein networks and single-cell data[J]. bioRxiv, 2023: 2023.07. 18.549602.
神经科学
视觉感知重建
从人类脑活动中重建视觉感知能够为理解大脑如何表征世界提供了巨大的帮助。然而由于大脑活动与视觉感知之间的关系非常复杂,这项任务向来极具挑战性。得益于生成式模型的出现,特别是生成扩散模型使得我们能够根据文本生成逼真的图像。如果我们将脑活动数据解释为“文本”,那么我们就能够根据脑活动数据生成图像。令人惊讶的是,从脑活动数据重建感知的图像并不需要重头训练深度学习网络,而只需在面向通用数据预训练而来的Stable Diffusion模型基础上进行部分改动即可。

看到的图像(第一行)和从fMRI信号重建的图像(第二行)
联合行为及神经分析的表征学习
理解神经活动与行为之间的联系是神经科学的基本目标。随着我们同时记录神经活动和行为数据的能力不断提升,当前的主要挑战日益集中于识别神经活动和行为数据间潜在的关联关系。UMAP及t-SNE等应用广泛的方法无法将时间信息纳入考量并极易受到无关因素的影响。Schneider等[1]提出了一种基于对比学习的CEBRA算法,该方法利用神经编码中的时间结构有力地弥补了现有方法的不足,并能够适用于假设驱动和发现驱动的研究。
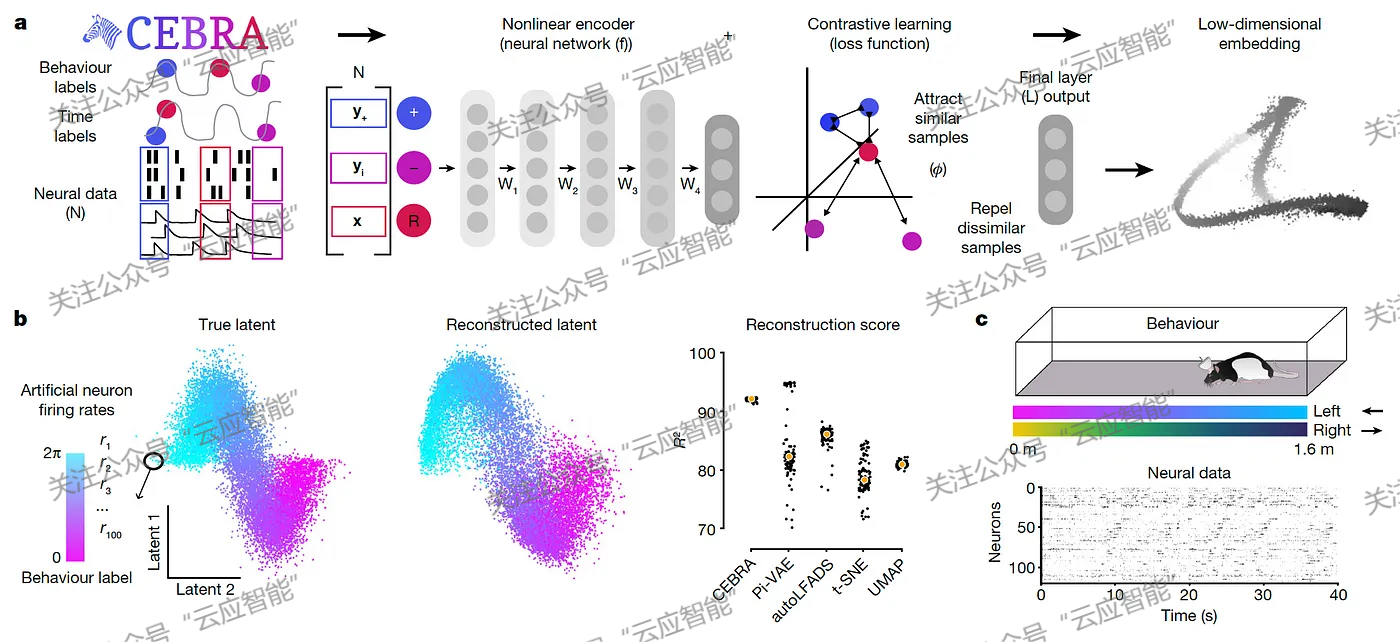
CEBRA算法流程图
参考文献
[1] Schneider S, Lee J H, Mathis M W. Learnable latent embeddings for joint behavioural and neural analysis[J]. Nature, 2023, 617(7960): 360-368.
医学
医学多模态基础模型
随着大模型的发展,Moor等人[1]提出了一种通用医疗人工智能(GMAI),该模型能够理解多模态数据,如影像、电子健康记录、实验室结果、基因组学、图表或医学文本。GMAI在大规模、多样化的多模态数据上以自监督方式进行预训练,并能应用于多种医疗任务中。Singhal等[2]整理了一个大规模的医学领域问答数据集,并基于PaLM[3]提出了一个医学领域的大型语言模型,称为Med-PaLM。这是第一个在美国医师执照考试(USMLE)中超过及格线(>60%)的AI模型,第二版Med-PaLM(Med-PaLM 2)更是成为第一个在回答USMLE问题时达到与人类专家相当水平的模型.医学影像数据中的图像-文本对也为多模态学习提供了基础。利用临床医生在公共论坛中分享的图像-文本对,Huang等[4]开发了一种面向病理图像的多模态基础模型。
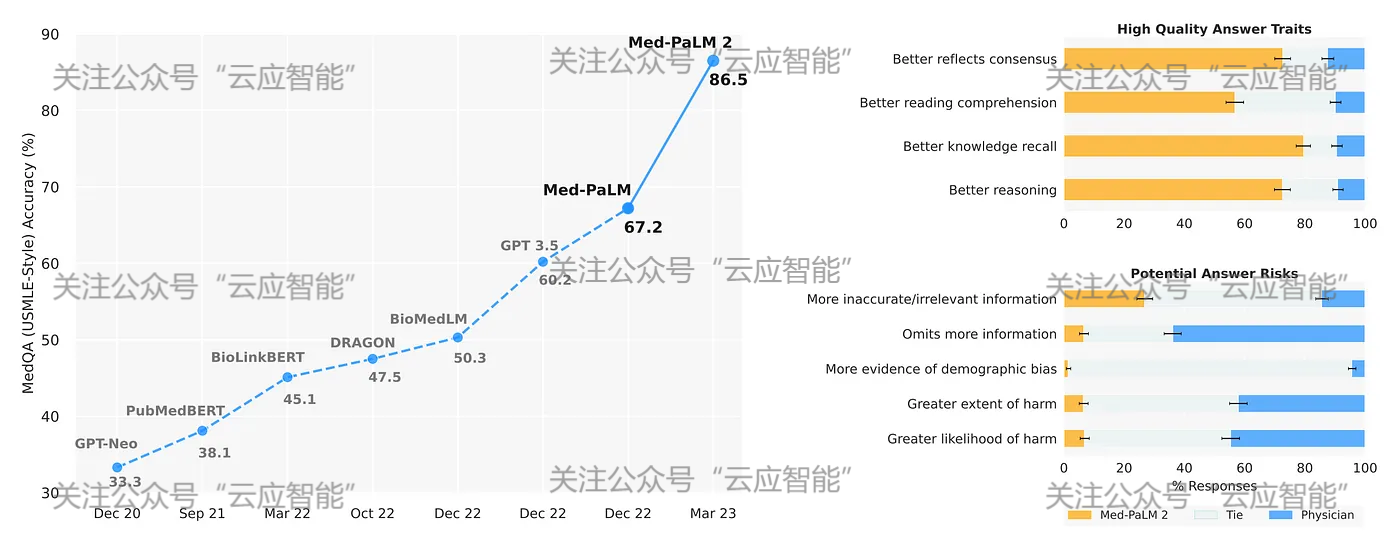
人工智能模型在医学问答中效果统计图
公共卫生:从疫情前数据预测病毒逃逸
-
实验方法需要使用宿主多克隆抗体进行测试; -
现有的计算方法严重依赖于现有毒株的流行情况来可靠地预测相关变种。
EVEscape示意图
医学图像人工智能应用
在深度学习中,捷径学习(Shortcut Learning)是指模型通过利用数据中某些表面特征或简单模式来快速完成任务,而不是学习到真正的底层规律或复杂结构。这种现象导致模型虽然在训练集和测试集上表现良好,但在面对真实世界的多样化和复杂性时,泛化能力较差。为解决医学人工智能模型中的捷径学习问题,DeGrave等[6]利用生成式模型生成“对抗”图像以理解五个医学图像分类器的“推理”过程,使人工智能模型的推理过程在医学上更具可解释性。
在通用领域,Segment-Anything Model(SAM)[7]构建了迄今为止最大的分割数据集,包括1100多万张图像以及超过10亿个掩模,SAM在零样本任务中展现出优越的图像分割能力。后续在SAM的基础上构建的模型(例如,对SAM进行微调或基于SAM的迁移学习)在医学图像分割方面展现出了优越的性能。
参考文献
[2] Singhal K, Azizi S, Tu T, et al. Large language models encode clinical knowledge[J]. Nature, 2023, 620(7972): 172-180.
[3] Chowdhery A, Narang S, Devlin J, et al. Palm: Scaling language modeling with pathways[J]. Journal of Machine Learning Research, 2023, 24(240): 1-113.
[4] Huang Z, Bianchi F, Yuksekgonul M, et al. A visual–language foundation model for pathology image analysis using medical twitter[J]. Nature medicine, 2023, 29(9): 2307-2316.
[5] Thadani N N, Gurev S, Notin P, et al. Learning from prepandemic data to forecast viral escape[J]. Nature, 2023, 622(7984): 818-825.
[6] DeGrave A J, Cai Z R, Janizek J D, et al. Auditing the inference processes of medical-image classifiers by leveraging generative AI and the expertise of physicians[J]. Nature Biomedical Engineering, 2023: 1-13.
化学
材料合成
基于人工智能的化学材料合成是利用机器学习、深度学习和自动化技术来设计、预测并优化化学合成过程的新兴领域。Koscher等[1]结合预测模型和生成模型,设计和合成小分子有机物,成功执行了超过3000个反应,发现了303种未报告的dye-like的分子化合物。Szymanski等[2]在无机材料合成方面建立了一个名为A-Lab的实验室,通过机器人执行实验以验证AI生成的候选分子,该项目成功在58次试验中成功合成了41种化合物。Strieth-Kalthoff等[3]利用云计算和远程实验设计,使得设计活动可以以分布式、异步的方式进行,发现了21种激光发射材料。Zhu等[4]也基于人工智能开发了从火星陨石中发现氧生成催化剂自动化方法。
自主分子合成框架
尽管自主分子合成框架仍处于早期阶段,但它展示了在实际科学发现过程中协调人工智能能力和自动化技术的巨大潜力。这一框架的成功不仅依赖于先进的人工智能技术,还需要高效的实验执行和精确的数据管理。未来,随着技术的进一步发展和集成,自主分子合成框架有望在化学和材料科学等领域带来更多突破。
材料发现
在材料发现领域,进行大规模原子级模拟并准确捕捉电子相互作用是至关重要但又充满挑战的任务。传统的力场方法虽然在推进这些研究中发挥了重要作用,但往往在精度上有所不足。因此,需要一种更准确的力场方法来提高ab initio molecular dynamics(AIMD)的逼真度和可靠性。由深度学习工具驱动的原子级建模新方法——晶体哈密顿图神经网络(CHGNet)在2023年由邓等[5]提出。CHGNet在涵盖了超过150万个无机结构的Materials Project Trajectory数据集进行预训练,能够从未知原子电荷的晶体结构预测能量、力、应力和磁矩。DeepMind的GNoME团队[6]通过人工智能工具“材料探索图形网络(以下简称GNoME)”发现了多达220万种理论上稳定,但绝大部分在实验上尚未实现的晶体结构。Musaelian等[7]人利用一种名为Allegro[8]的深度等变神经网络在Perlmutter超级计算机上成功模拟了包含4400万原子的HIV衣壳结构,实现了前所未有的精度和速度。
过渡态理解
化学反应的核心在于理解反应物如何转变为产物,而过渡态作为反应路径上能量最高点的短暂存在,对于这种理解至关重要。然而,过渡态极难在实验中分离和表征,传统的量子化学方法虽然有效,但计算复杂且耗时。麻省理工学院和康奈尔大学的研究人员开发了OA-ReactDiff[9],这是一种扩散模型,能够将三维的反应物、过渡态结构和产物描述为一个联合分布。OA-ReactDiff不仅满足化学反应中的对称性,还实现了前所未有的性能提升。借助该模型,可以在六秒内生成准确的过渡态结构,相对于传统基于优化的方法,速度提升了1000倍。此外,由于其扩散模型的随机性,OA-ReactDiff能够探索传统化学直觉可能忽略的非预期反应路径,为化学反应探索提供了新的视角。未来,生成扩散模型在化学反应中的应用前景广阔,包括模拟复杂的燃烧反应、探索地球早期生命演化中的反应以及设计新型催化剂等。
基于生成扩散模型的过渡态理解
化学大模型智能体应用
随着ChatGPT的普及,语言大模型在自动化科学发现方面展现出广阔前景,不仅在人机互动方面展现了巨大潜力,还能通过与互联网和实验设备的交互实现复杂的科研任务。基于大模型构建智能体如Coscientist[10]和ChemCrow[11],已经能够规划具有特定目标的实验(例如合成布洛芬),并通过调用搜索互联网、编写和执行Python代码、查阅实验设备文档,以及运行实验等模块以实现多种功能。虽然这些研究目前仍处于概念验证阶段,但它们已经展示了大模型智能体的多功能性,如合成化合物、搜索文档、控制液体处理仪器,通过分析实验数据优化方案。随着这种方法的逐渐成熟,人类科学家将从繁琐的、劳动密集型任务中解放出来,能够更多地专注于创新性研究。
化学大模型智能体应用框架
参考文献
[1] Koscher B A, Canty R B, McDonald M A, et al. Autonomous, multiproperty-driven molecular discovery: From predictions to measurements and back[J]. Science, 2023, 382(6677): eadi1407.
[11] Bran A M, Cox S, Schilter O, et al. Chemcrow: Augmenting large-language models with chemistry tools[J]. arXiv preprint arXiv:2304.05376, 2023.
物理学
天体物理学
IceCube团队[1]的进展代表了天体物理学领域的一个重要里程碑。通过利用人工智能算法来区分信号数据和背景数据,该研究团队实现了前所未有的精度,成功检测到来自银河系平面的高能中微子发射。这项研究采用了卷积神经网络(CNN)进行事件选择,其高推理速度使得事件选择能够应用更复杂的过滤策略。同时,为了确定物理事件的属性该研究还采用了一种结合最大似然估计和具有多重对称性的神经网络的混合重建方法。这些人工智能模型基于十年间的观测数据进行优化,学习在宇宙噪声的背景下精确定位中微子特征。实验结果表明,利用该方法银河系内的潜在中微子发射能够以4.5σ的显著性水平被揭示。这项研究的创新之处在于将人工智能应用于天体物理学中,不仅增强了天文台的检测能力,还为未来的天体物理探索提供了新的途径。
晶格量子色动力学
晶格量子色动力学(QCD)是研究夸克和胶子如何结合成质子、中子及其他强子的关键理论框架。尽管晶格QCD非常强大,但由于在晶格上进行量子场计算的复杂性,它面临显著的计算挑战。传统方法如蒙特卡罗模拟虽然被广泛使用,但由于临界慢化和拓扑冻结等问题,这些方法不仅需要大量计算资源,而且在某些情况下效率较低。近年来,基于人工智能的采样方案被提出,可能彻底改变这些计算,为相关研究提供了更高效的解决方案。
参考文献
[1] IceCube Collaboration*†, Abbasi R, Ackermann M, et al. Observation of high-energy neutrinos from the Galactic plane[J]. Science, 2023, 380(6652): 1338-1343.
地球科学
天气预报
由于大气条件的非线性动力学和复杂性,天气预报一直是一项具有挑战性的任务。而随着人工智能技术和计算能力的不断提升,基于人工智能的短期(数小时)和中期(数天到数周)的天气预报均取得了显著进展。如ClimaX[1]、GraphCast[2]、Pangu-Weather[3]、MetNet-3[3]和PreDiff[4]等模型,这些模型利用十数年的历史天气数据构建算法模型,实现高分辨率的时空预测。GraphCast采用图神经网络(Graph Neural Network, GNN)结构,并使用“编码器-处理器-解码器”(encoder-processor-decoder)配置来处理空间结构化的天气数据。GraphCast能够有效地捕捉天气数据的空间关系,进而提高预测的准确性。PreDiff提出了一种条件潜在扩散模型(Conditional Latent Diffusion Model)用于概率预测。该模型通过学习天气变量之间的潜在关系,提供概率性的天气预报,能够更好地应对天气预报中的不确定性。ClimaX基于Transformer架构分别构建了全球尺度及区域尺度的基础模型,适用于任何天气和气候建模任务。
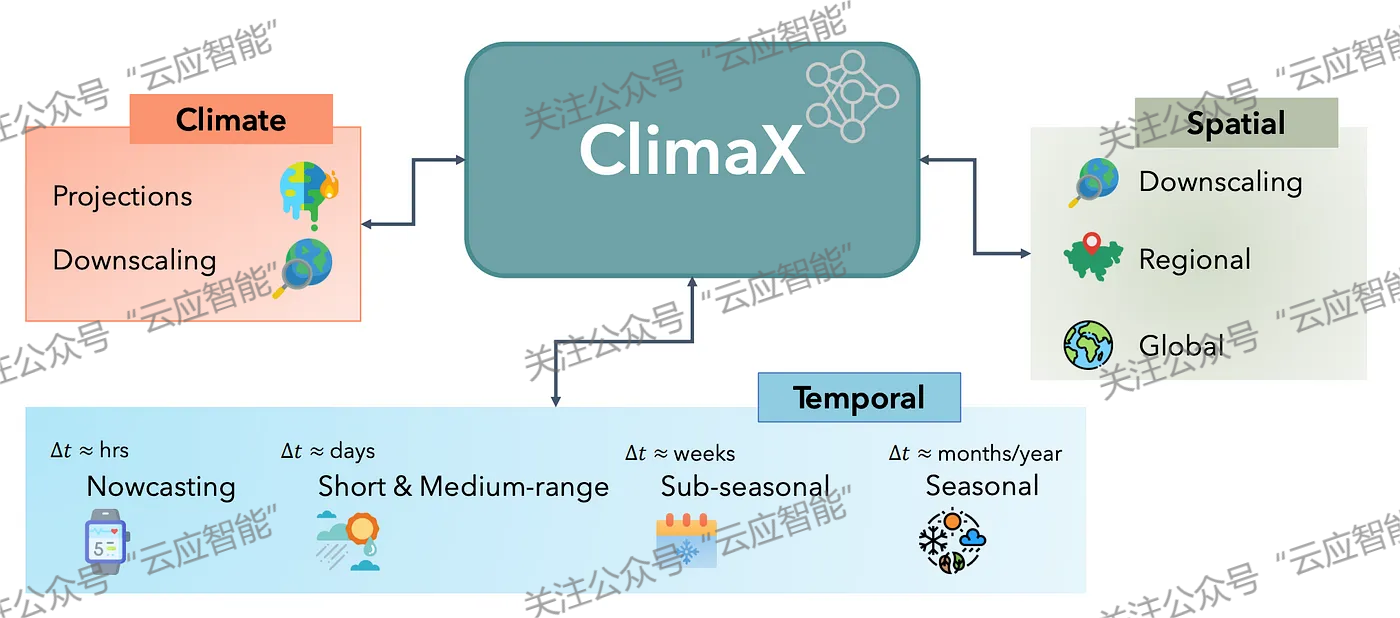
由人工智能驱动的天气预报工作大多在大型科技公司内部进行。一者虽然这些模型的推理对算力要求相对不高,但训练这些大规模、高分辨率的模型通常需要高性能的计算硬件。二者训练这些模型所使用的数据集,如欧洲中期天气预报中心(ECMWF)的ERA5再分析档案和国际耦合模式比较计划(CMIP)中的CMIP6数据,都需要在训练模型之前进行全面的数据清理和整理工作。随着极端天气的日益频发和气候变化的持续进行,理解地球系统对气候干扰的响应变得至关重要。这将为地球科学的许多领域提供基础,包括水文(特别是水文气象学)、海洋学,以及更实际的自然灾害响应计划和早期预警系统的开发。
数值物理模型替代
在地球科学不断发展的领域中,寻求准确预测和高效决策工具的追求引发了对人工智能(AI)和机器学习(ML)技术的范式转变。传统方法通常受限于有限的数据集和计算资源,尤其是在地下勘探、冰冻圈动态和火山学等领域。然而,最近人工智能辅助模型的创新正在彻底改变研究者解决这些挑战的方式。Wen等人关于碳捕集与储存的研究、Meray等人关于地下水流与污染物传输的研究以及Chattopadhyay等人关于海洋环流的研究。这些研究的训练数据都基于数值物理模型,训练完成后的人工智能模型相较于原始的数值物理模型显著减轻了计算负担。此外,结合模拟数据和物理约束混合模型也越来越受到研究者的关注。一种方向是将物理约束条件(包括初始条件、边界条件、领域知识和偏微分方程)纳入损失函数,如岩石Iwasaki等[5]开展的冰盖硬度反演研究,Meray等[6]人水文建模研究。另一种方向是将物理模型与机器学习模型相结合,例如Shen等[7]的微分模型。该模型利用物理定律和现有数据训练机器学习模型,通过自动微分学习更好的地球系统模型。
参考文献
[1] Nguyen T, Brandstetter J, Kapoor A, et al. Climax: A foundation model for weather and climate[J]. arXiv preprint arXiv:2301.10343, 2023.
[7] Shen C, Appling A P, Gentine P, et al. Differentiable modelling to unify machine learning and physical models for geosciences[J]. Nature Reviews Earth & Environment, 2023, 4(8): 552-567.
最新文章



ARM取消高通指令集、IP许可,再次验证中国自主可控之路
2577
2024-10-27
随着苹果与高通的决裂,ARM与高通的分割,知识产权上的影响势必会重塑格局。中国企业应该多发挥规则制定的作用,为未来20年奠定最优的知识产权发展空间。

LexisNexis公司发布最新Wi-Fi 6专利实力报告,华为、高通争抢头名
2828
2024-10-27
美国LexisNexis公司发布了《谁在引领Wi-Fi 6专利竞赛?》的报告,随文章一起看看值得关注的观点。

刚刚,诺贝尔物理学奖破天荒颁给「AI教父」!Hinton成首位图灵奖诺贝尔物理学奖双料得主
2801
2024-10-13
爆冷!2024年的诺贝尔物理学奖,花落John Hopfield和Geoffrey Hinton,理由是运用物理学原理训练人工神经网络。委员会宣布获奖名单时,所有人倒吸一口冷气。现在,网友已经炸锅了。
加入我们
